使用特征归因检测对抗样本
Abstract
- 通过对特征归因得分的尺度估计进行阈值化进行对抗样本的检测
- 采取多层特征归因应对具有混合置信度的攻击
- 在攻击者可以完全访问分类器的情况下依然保持较好的检测效果
1.Introduction
虽然一系列工作试图解释为什么存在对抗样本,但尚未对根本原因进行全面分析,这主要是因为深层原因神经网络具有复杂的函数形式,因此很难获得数学特征。另一方面,特征归因是一种被广泛研究解决神经网络黑盒性质的方法:给定一个预测模型,对每个输入实例输出一个与底层特征相关的重要性得分向量。特征归因已被用来提高机器学习模型的透明度和公平性。
本文研究了特征归因在检测对抗样本中的应用。观察到边界附近的对抗样本的特征归因图总是与相应的原始示例的特征归因图不同。图 1 显示了一个激励示例,它演示了将 CIFAR-10 中的图像输入残差神经网络以及留一法 (LOO) 的相应特征归因。后者通过观察在 C&W 攻击的最坏情况扰动之前和之后擦除输入的每个像素对模型的影响来解释神经模型的决策。虽然原始图像上的扰动在视觉上难以察觉,但特征属性却发生了巨大的变化。进一步观察到,这种差异可以通过描述特征不一致的简单统计来概括,这些统计能够区分对抗样本和自然图像。推测这是因为对抗样本往往会将样本扰乱到决策面上的不稳定区域。
上述观察产生了一种检测决策边界附近的对抗样本的有效方法。另一方面,也存在模型具有高置信度的对抗样本。还观察到一个有趣的现象:即使对于高置信度的对抗样本,神经网络的中间层仍然包含不确定性信息。基于这一观察,将不稳定方法推广到合并多层特征归因,其中计算中间层的归因分数而不会产生额外的模型查询。
2.相关工作
特征归因
已经提出了多种方法来分配特征归因分数。对于应用模型的每个特定实例,归因方法通过实例周围的局部线性模型逼近目标模型,为每个特征分配重要性分数。一类方法假设模型的可微性,并通过梯度将预测传播到特征。包括直接使用梯度(显着性图)、逐层相关性传播(LWRP)及其改进版本 DeepLIFT和积分梯度。
另一类方法是基于扰动的,因此与模型无关。给定一个实例,通过使用预先指定的参考值屏蔽不同的特征组来生成多个扰动样本。实例的特征属性是根据模型对这些样本的预测分数来计算的,包括留一法、LIME和 KernelSHAP。
观察结果表明,特征归因的敏感性可能源于模型的敏感性,而不是归因方法。这激发了本文通过归因方法检测对抗样本。
对抗攻击
对抗攻击试图以最小的扰动改变给定模型对原始实例的预测,从而产生对抗样本。对抗样本可以分为有针对性的或无针对性的,具体取决于目标是将受到干扰的实例分类为给定的目标类还是与正确类不同的任意类。攻击还因用于表征最小扰动的距离类型而异。 ∞、0 和 2 距离是最常用的距离。 Goodfellow、Shlens 和 Szegedy 提出的快速梯度符号法 (FGSM) 是一种最小化 ∞ 距离的有效方法。 Kurakin、Goodfellow、Bengio 和 Madry 等人提出了 ∞-PGD (BIM),它是 FGSM 的迭代版本,它以更小的扰动实现了更高的成功率。 Moosavi-Dezfooli、Fawzi 和 Frossard 提出的 DeepFool 通过迭代线性化过程最小化 2 距离。 Carlini 和 Wagner 提出了有效的算法来为这三个距离中的每一个生成对抗样本。特别是,Carlini 和 Wagner 提出了一种能够控制对抗样本置信度的损失函数。 (Papernot et al. 2016a) 提出的基于雅可比行列式的显着图攻击 (JSMA) 是一种用于 0 度量扰动的贪婪方法。最近,出现了几种仅依赖于概率分数或决策的黑盒对抗性攻击。 Ilyas、Engstrom 和 Madry 引入了基于分数的方法,使用零阶梯度估计来制作对抗样本。 Brendel、Rauber 和 Bethge 引入了边界攻击,作为一种最小化 2 距离的黑盒方法,不需要访问梯度信息,仅依赖于模型决策。
我们在实验中证明,我们的方法能够检测这些攻击生成的对抗样本,无论是基于距离、置信度或是否使用梯度信息的攻击。
对抗防御和检测
为了提高神经网络的鲁棒性,人们提出了各种方法来防御对抗性攻击,包括对抗性训练,分布平滑,防御蒸馏,生成模型、特征压缩、随机模型和可验证防御。这些防御通常涉及模型训练过程中的修改,这通常需要更高的计算或样本复杂性,并导致准确性损失。
作为对之前防御技术的补充,另一种工作重点是在测试阶段筛选出对抗样本,而不涉及原始模型的训练。PCA 等数据转换被用来从神经网络的输入和层中提取特征以进行对抗检测。
与我们的工作最相关的是,Tao 等人提出识别对个体属性至关重要的神经元以检测对抗样本,但他们的方法仅限于面部识别中的模型。相反,我们的方法适用于不同类型的图像数据。张等人提出通过在输入的显着性图上训练神经网络来识别对抗性扰动。然而,他们的方法依赖于额外的神经网络,当攻击者扰乱图像以同时愚弄原始模型和新神经网络时,这些神经网络很容易受到白盒攻击。正如我们将在实验中证明的那样,我们的方法在白盒攻击下实现了有竞争力的性能。
3.具有特征归因的对抗性检测
我们通过观察有或没有对抗性扰动的特征归因来激发我们的方法。然后我们讨论量化归因分散度的指标。最后,我们将我们的方法扩展到多层版本,用于检测具有混合置信水平的对抗样本。
4.扰动前后的特征归因
对抗性攻击旨在以最小的样本扰动改变模型的预测,从而使人类无法检测原始图像 x 与其扰动版本 x′ 之间的差异。然而我们观察到 φ 对 x 和 x′ 之间的微小差异很敏感。图 1 显示了原始图像 x 及其受到 C&W 攻击的对抗扰动对应图像 x’ 的归因图 φ(x)、φ(x’)。即使用人眼,我们也可以观察到原始图像和对抗图像的归因图的明显差异。特别是,对抗性图像的重要性得分具有更大的分散性,如图 1 所示。
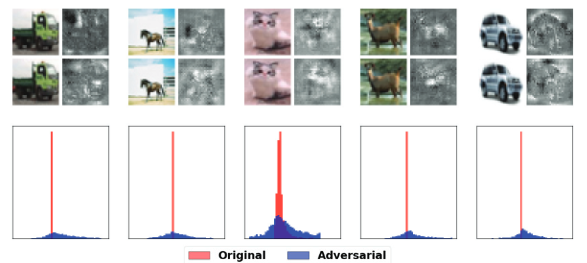
图 1:第一行显示原始 CIFAR-10 示例及其相应的特征属性。第二行显示对抗性示例及其相应的特征属性。第三行绘制原始特征和对抗性特征归因的直方图。
5.量化特征归因图中的分散度
如图 1 所示,由于原始图像和对抗性图像之间重要性分数分布的明显差异,我们建议使用特征归因中的统计离散度测量来检测对抗样本。特别是,我们尝试了标准差(STD)、中位绝对差(MAD)(条目与其中位数之间的绝对差值的中位数)以及四分位距(IQR)(即差值)。
我们观察到,在对抗性扰动图像的模型的特征贡献之间存在较大的离散度,我们称之为特征不一致。这种差异在不同图像中是普遍存在的。
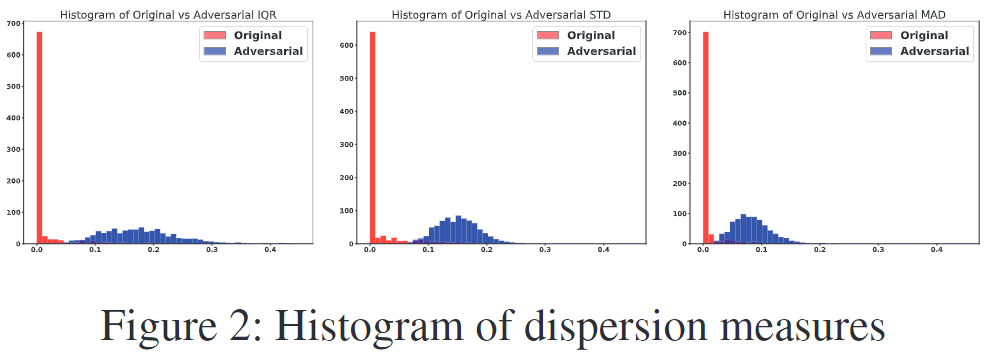 图 2 比较了来自 CIFAR-10 的自然测试图像上的 ResNet 特征归因的这三种离散度测量的直方图与对抗性扰动图像上的直方图,其中对抗性扰动是由 C&W Attack 执行的。我们可以看到自然图像和对抗图像之间的 STD、MAD 和 IQR 分布存在显着差异。除了相应的原始图像之外,大多数受到对抗性扰动的图像在特征归因上比任意自然图像具有更大的分散性。我们建议通过对特征归因图的 IQR 进行阈值化来区分对抗图像和自然图像。在补充材料中,我们展示了在 CIFAR-10 上使用 ResNet 的三种分散度量在三种不同攻击中进行对抗性检测的 ROC 曲线。所有这三项指标都产生了具有竞争力的表现。在本文的其余部分,我们坚持使用 IQR,它很稳健,并且在三者中具有稍微优越的性能。
图 2 比较了来自 CIFAR-10 的自然测试图像上的 ResNet 特征归因的这三种离散度测量的直方图与对抗性扰动图像上的直方图,其中对抗性扰动是由 C&W Attack 执行的。我们可以看到自然图像和对抗图像之间的 STD、MAD 和 IQR 分布存在显着差异。除了相应的原始图像之外,大多数受到对抗性扰动的图像在特征归因上比任意自然图像具有更大的分散性。我们建议通过对特征归因图的 IQR 进行阈值化来区分对抗图像和自然图像。在补充材料中,我们展示了在 CIFAR-10 上使用 ResNet 的三种分散度量在三种不同攻击中进行对抗性检测的 ROC 曲线。所有这三项指标都产生了具有竞争力的表现。在本文的其余部分,我们坚持使用 IQR,它很稳健,并且在三者中具有稍微优越的性能。
6.多层 LOO:检测具有混合置信度的攻击
对抗样本的表征可能只成立对于决策边界附近的对抗性例子。不幸的是,特征归因图的 IQR 也遇到了同样的问题。为了检测具有混合置信水平的对抗性图像,需要扩展方法来捕获模型输出层之外的特征属性的分散性。对于在像素空间中其原始示例的一个小邻域内的对抗样本,在与原始示例不同的类别的输出层上获得高置信度,特征表示沿着方向逐渐偏离其原始示例的特征表示。
为了协调不同神经元之间的尺度差异,我们在保留训练集上对来自不同神经元的特征归因的分散度进行逻辑回归,以区分对抗样本和原始图像。我们方法的多层扩展称为“ML-LOO”。
7.实验
我们对 ML-LOO 进行了实验评估,并将我们的方法与几种最先进的检测方法进行了比较。然后我们考虑攻击具有不同置信度的设置。我们进一步评估各种检测方法对未知攻击的可转移性。最后,我们评估我们的方法在知道我们检测器存在的白盒攻击者下的性能。
已知攻击
- 将我们的方法与最先进的检测算法进行比较,包括 LID和 KD+BU
- 三个数据集:MNIST、CIFAR-10 和 CIFAR-100,采用标准训练/测试分割。对于每个数据集,我们通过每种攻击方法从正确分类的测试图像中生成了 2,000 个对抗样本。其中,1,000 张对抗性图像以及相应的 1,000 张自然图像用于 LID、Mahalanobis 和我们的方法的训练过程。
- 对于 MNIST,我们使用了一个由 32 个滤波器卷积层组成的卷积网络,后面是一个包含 1024 个单元的隐藏密集层。每个卷积层后面都有一个最大池化层。
- 对于 CIFAR-10 和 CIFAR-100,我们分别训练了 20 层 ResNet和 121 层 DenseNet。
- 使用以下攻击方法,按其优化的规范进行分组:
- L∞: FGSM , L∞-PGD.
- L2: C&W , Deep-Fool,Boundary Attack.
- L0: JSMA.
- 真阳性率(TPR)是被分类为对抗性的对抗样本的比例。 假阳性率(FPR)是被分类为对抗性的自然图像的比例。我们将 ROC 曲线的曲线下面积 (AUC) 报告为性能评估,并通过将 FPR 阈值设置为 0.01、0.05 和 0.1 来报告真阳性率,因为将错误分类的自然图像保持在较低比例是可行的。
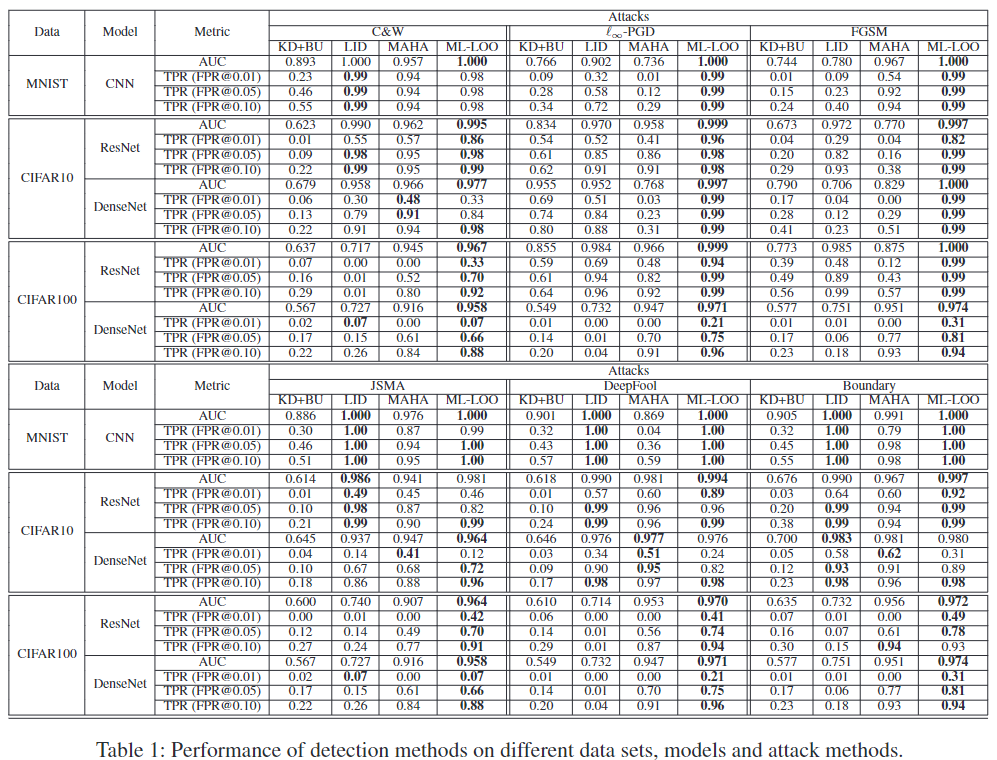 结果如表 1 所示,CIFAR-10 与 ResNet 的 ROC 曲线如图 3 所示。其余图可以在补充材料中找到。 ML-LOO 在不同的数据集、针对 2 和 ∞ 距离优化的所有攻击模型中表现出优于其他三种检测方法的性能。通过将 FPR 控制在 0.1,我们的方法能够找到大多数现有攻击生成的超过 95% 的对抗样本。
结果如表 1 所示,CIFAR-10 与 ResNet 的 ROC 曲线如图 3 所示。其余图可以在补充材料中找到。 ML-LOO 在不同的数据集、针对 2 和 ∞ 距离优化的所有攻击模型中表现出优于其他三种检测方法的性能。通过将 FPR 控制在 0.1,我们的方法能够找到大多数现有攻击生成的超过 95% 的对抗样本。
不同置信度的攻击
当 C&W 攻击生成的对抗样本的置信度发生变化时,LID 会失败。我们考虑针对 2 次和 ∞ 次攻击来生成具有不同置信水平的对抗性图像。
用于优化 2 距离的 C&W 攻击 我们考虑 C&W 攻击的三种设置:低置信度 (C&W-LC)、混合置信度 (C&W-MIX) 和高置信度 (C&W-HC)。我们为 C&W-LC 设置置信度参数 c = 0,为 C&W-HC 设置 c = 50。对于混合置信度C&W攻击,我们在生成对抗性图像时,使用从{1,3,5,···,29}中随机选择的等式(2)中的置信度参数,从C&W攻击中生成对抗性图像,使得对抗图像的置信水平分布与原始图像的置信水平分布相当。三种设置下图像的置信度以及原始图像的置信度如图4所示。
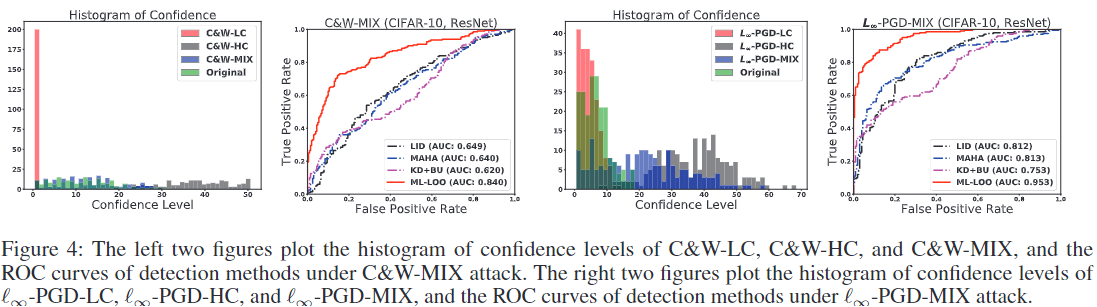 我们在 CIFAR-10 上训练的 ResNet 上进行了实验,使用混合置信度 C&W 攻击生成的 1, 000 张对抗图像以及相应的原始图像作为 LID、Mahalanobis、KD+BU 和我们的方法的训练数据。我们在由三个版本生成的一组不同的原始图像和对抗性图像上测试检测方法:低置信度 C&W 攻击 (c = 0)、高置信度 C&W 攻击 (c = 50) 和混合置信度 C&W 攻击。
我们在 CIFAR-10 上训练的 ResNet 上进行了实验,使用混合置信度 C&W 攻击生成的 1, 000 张对抗图像以及相应的原始图像作为 LID、Mahalanobis、KD+BU 和我们的方法的训练数据。我们在由三个版本生成的一组不同的原始图像和对抗性图像上测试检测方法:低置信度 C&W 攻击 (c = 0)、高置信度 C&W 攻击 (c = 50) 和混合置信度 C&W 攻击。
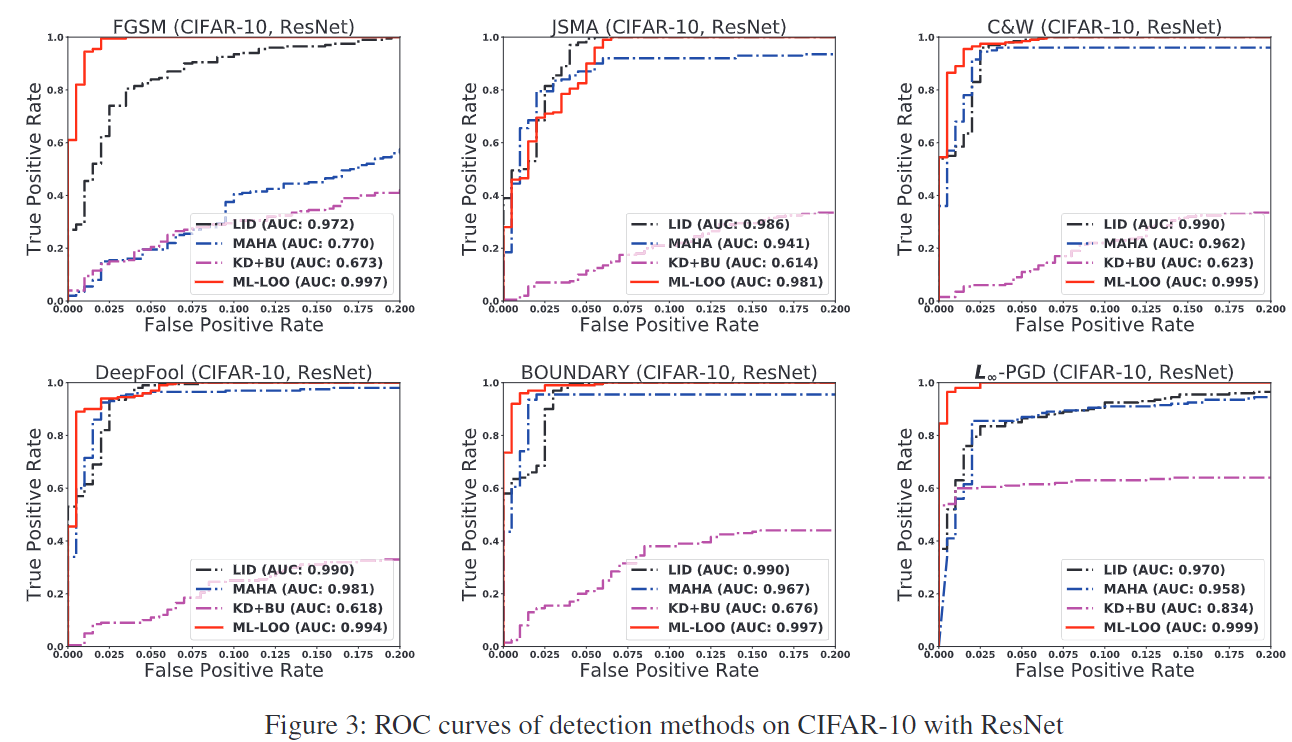
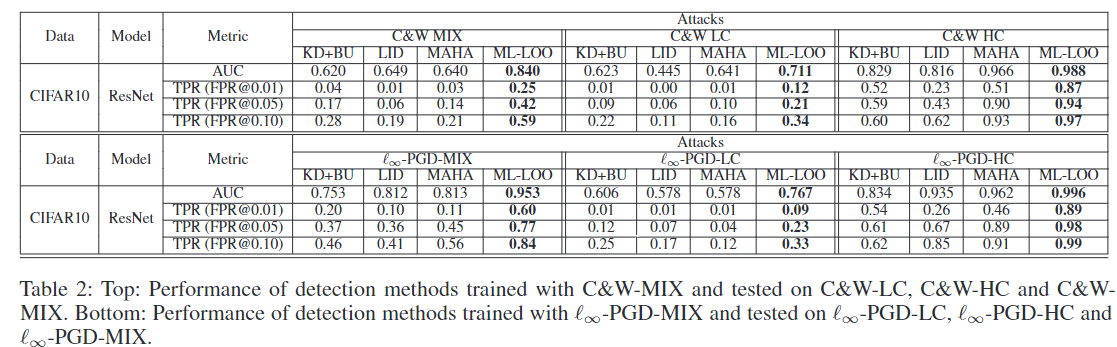 表 2(上)和图 4(左)显示了不同 FPR 阈值下的 TPR、AUC 和 ROC 曲线。 Mahalanobis、LID 和 KD+BU 无法有效检测混合置信度的对抗样本,而我们的方法在这三种设置中对于对抗性图像的表现始终更好。
表 2(上)和图 4(左)显示了不同 FPR 阈值下的 TPR、AUC 和 ROC 曲线。 Mahalanobis、LID 和 KD+BU 无法有效检测混合置信度的对抗样本,而我们的方法在这三种设置中对于对抗性图像的表现始终更好。
用于优化 ∞ 距离的 L∞-PGD L∞-PGD 也称为 BIM,通过使用以下迭代更新原始图像来搜索对抗样本: xN +1 = Clipx,ε{xN + αsign(∇X J(xN , ytrue))}, (3) 其中 ytrue 是原始类,J 是交叉熵损失,Clip 运算符将图像按元素剪辑为ε-邻域。对于混合置信度 ∞-PGD 攻击,我们通过从 {1, 2, 3, 4, 5, 6, 7, 8}/255。混合置信度 ∞-PGD 攻击图像的置信度如图 4 所示。我们使用混合置信度 ∞-PGD 生成的 1, 000 张对抗性图像及其相应的原始图像作为训练。所有检测方法的数据。我们报告了从三个版本生成的对抗性图像的结果:高置信度 ∞-PGD (ε = 0.03)、低置信度 ∞-PGD (ε = 0.005) 和混合置信度 ∞-PGD用于生成训练数据。对应的原始图像与训练图像不同。表 2(下)和图 4(右)显示了不同 FPR 阈值下的 TPR、AUC 和 ROC 曲线。 Mahalanobis、LID 和 KD+BU 无法有效检测混合置信度的对抗样本,而我们的方法在这三种设置中表现明显更好。

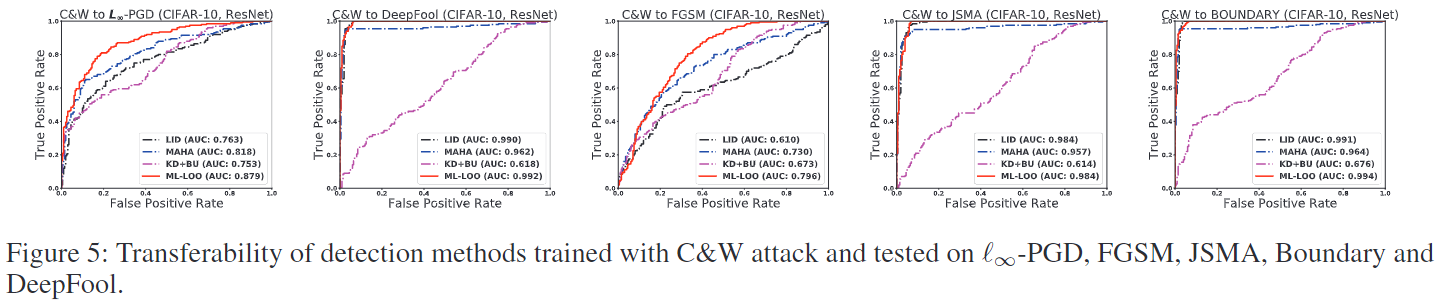
可迁移性
在本实验中,我们通过在一种攻击方法生成的对抗样本上训练检测方法来评估不同方法的可迁移性,并对不同攻击方法生成的对抗样本进行评估。我们在 C&W 攻击生成的对抗样本上训练所有方法,并对其余攻击方法生成的对抗样本进行评估。在 MNIST、CIFAR-10 和 CIFAR-100 数据集上进行实验。表3报告了不同FPR阈值下的AUC和TPR。所有针对C&W攻击训练的方法都能够检测未知攻击生成的对抗样本,即使优化距离为无穷大,或者攻击不是梯度的。这表明攻击可能具有一些共同特征。我们的方法始终产生略高的 AUC,并且当 FPR 控制得很小时,TPR 显着更高。
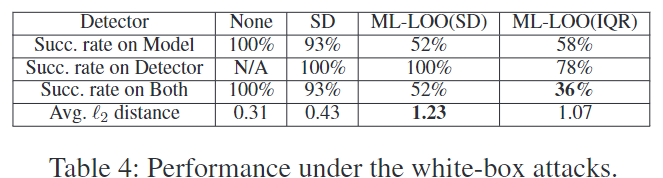
白盒评估
之前的实验是在“灰盒”威胁模型中进行的,攻击者可以访问梯度等模型细节,但无法访问检测器的设计。 “白盒”设置假设有一个更强的威胁模型,攻击者确切地知道我们的检测器是如何构建的及其参数。在之前的对抗性检测研究中经常缺少这样的设置。先前的工作(例如 LID 和 KD+BU)已被证明在这种设置下会失败(Carlini 和 Wagner 2017a;Athalye、Carlini 和 Wagner 2018)。我们评估 ML-LOO 在此设置中的性能。 ……
8.结论
在本文中,我们引入了一种新的框架,通过捕获原始示例和对抗样本之间特征归因分数的缩放差异来检测具有多层特征归因的对抗样本。我们表明,我们的检测方法在检测各种攻击方面优于其他最先进的方法。它还在检测不同置信水平的对抗样本、检测其他攻击转移的示例以及攻击者完全访问检测器时表现出强大的性能。 ML-LOO 的局限性之一是查询效率低下。在检测阶段,查询数量随着每个输入的特征数量而变化。未来的工作可能会通过随机采样像素来计算特征归因分数来解决这个问题。